![]()
農業に関する情報を発信します
2019.4.8
みどりクラウドのデータ分析をしているS.Fです。今回はセンサーデータをどのように活用できるかという視点で、分析/検討を行いましたのでご紹介させて頂きます。

今回はみどりボックスに搭載されている「土壌水分センサー」で出来ること、について考察してみました。このセンサーは土壌内の水分を体積含水率にて表現しており、土壌内の水分量の変化を見ることが出来ます。土壌水分量の値を参考にして潅水をしている、と言うユーザー様もいらっしゃるかと思います。
今回はこの土壌水分センサーデータを用いて「潅水」を検出する方法を検討しました。これが実現できると下記のような面でメリットがあると考えています。
過去の潅水データを生産へフィードバックする
潅水作業の記録を自動化する(みどりノートへ自動反映)
潅水するべきタイミングで、潅水されているかを監視する
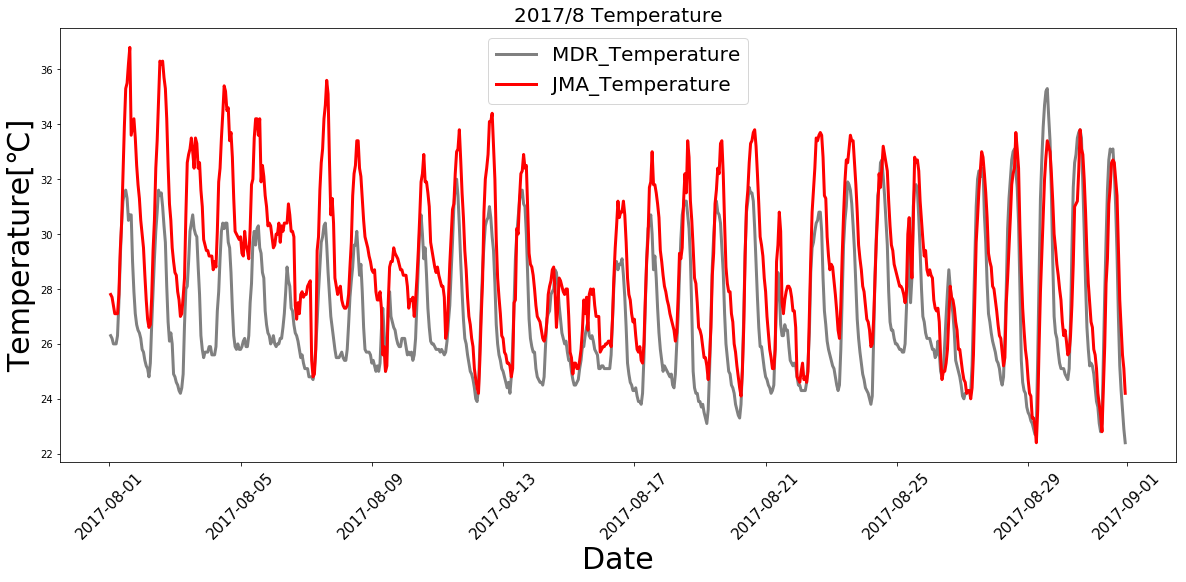
それでは、土壌水分量の時系列推移を見てみましょう。下図にサンプルデータを掲載します。
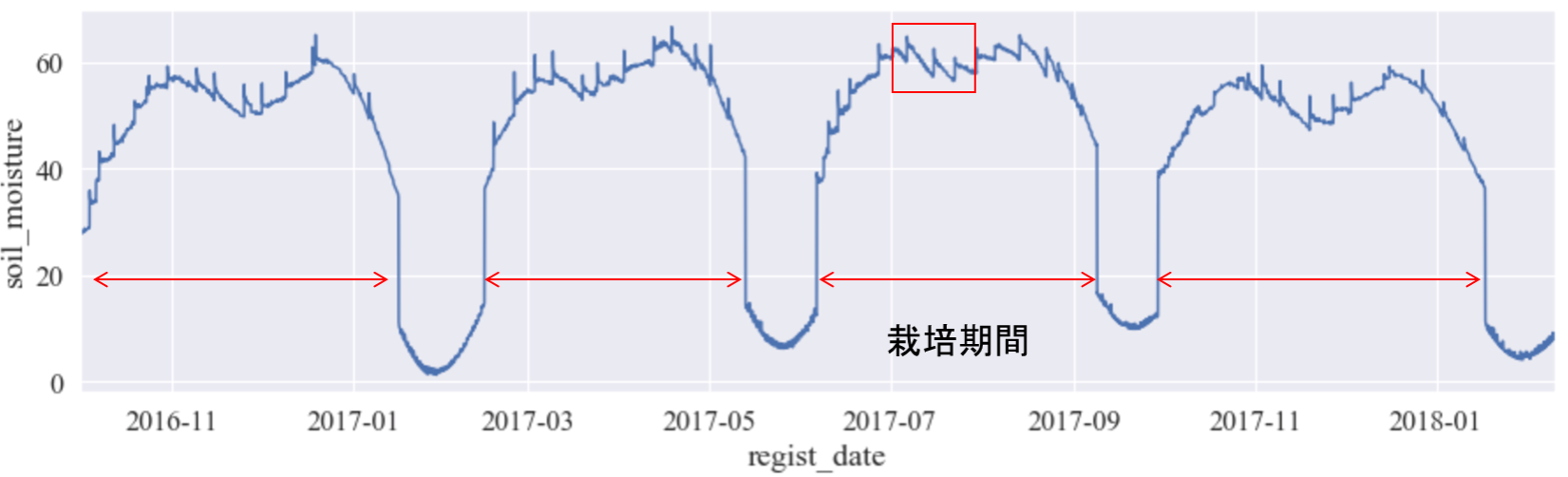
栽培期間中を見てみると、一定の範囲内で土壌水分が変動していることが確認できます。下に2017年の7月の範囲(上図赤枠部)を拡大したグラフを示します。
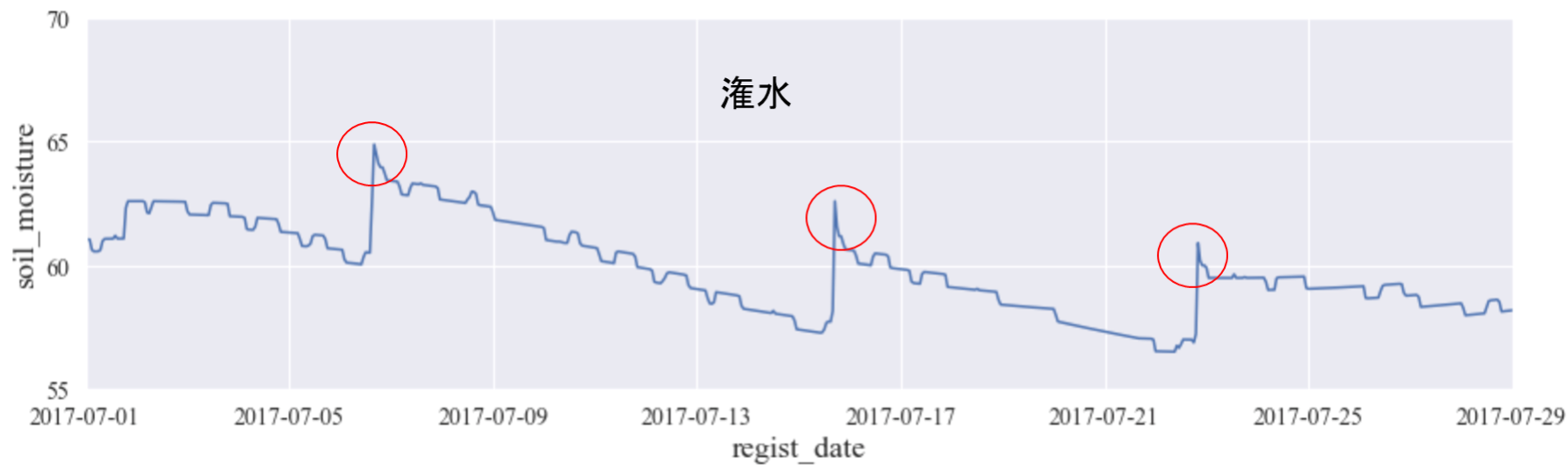
今回は、グラフ中に赤円で示した土壌水分の上昇が、「潅水」による上昇であると仮定して、検出方法を検討しました。
機械学習とは簡単に言うと、コンピュータにデータを学習させ、データのパターンや特性を発見し、予測をする手法です。今回の話で言うと、「土壌水分量」という時系列データをコンピュータに渡して学習させ、コンピュータに「潅水あり」か「潅水なし」を予測させることになります。「潅水あり」の予測は、即ち「潅水を検出する」と言うことです。それでは今回行った機械学習の手順、評価結果を説明します。
まずは、「教師データ」を作成する必要があります。教師データとは、どのデータが「潅水」にあたるかという、正解データのことです。コンピュータに学習させるためには何が「潅水あり」で、何が「潅水なし」なのかを教えてあげなくてはなりません。人間もテスト勉強をする時に、何が正解か分からなければ勉強になりませんよね?それと同じです。

次に、「教師データ」を学習用とテスト用に分割します。今回は時系列データの前半半分を「学習用」、後半半分を「テスト用」にしました。この分割は、「学習用」でコンピュータに学習をさせ、「テスト用」で学習モデルの性能を評価するために行います。もし分割をしなければ、学習したデータでテストを行う、つまりは答えを見ながらテストを受けるのと同じになり、予測性能を評価することが出来なくなってしまいます。ここまでが準備段階で、次から実際に学習を行います。
機械学習には、アルゴリズムの違いでたくさんの種類があります。今回は潅水検出を、「潅水あり」か「潅水なし」かに分類する分類問題と捉えて、分類問題によく利用される、ロジスティック回帰モデル、ランダムフォレストモデル、サポートベクターマシンモデル、勾配ブースティングモデルの4つを試してみました。(各モデルの詳細についてはここでは触れません。)
学習を終えたら、「テスト」用データで性能評価を行います。ここで評価指標について簡単に説明します。評価は「教師データ」と、各学習モデルの「予測結果」を下記のような「混同行列」を用いて比較します。ロジスティック回帰モデルの結果を例に出します。
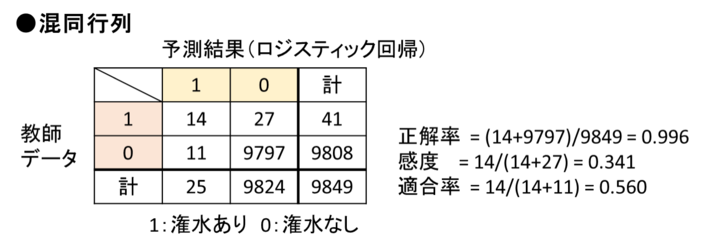
混同行列内の「1」「0」はそれぞれ「潅水あり」「潅水なし」を表しています。このようにデータ1つ1つに対し、「潅水あり」か「潅水なし」かのラベルを付け、学習モデルに予測させています。評価指標として「正解率」「感度」「適合率」を上げています。
「正解率」とは予測結果がどれだけ教師データと一致したかを表します。この例では、教師データ1に対して1を予測したのが14データ、教師データ0に対して0を予測したのが9797データなので、正解率は(14+9797)÷9849(全データ)= 0.996となります。
「感度」は教師データ1に対し、1を予測した割合を表します。これは実際の潅水の内、正しく検出出来た割合を意味し、高いほど良い予測が出来ていると言えます。この例では感度は14÷(14+27) = 0.341となります。
「適合率」は予測結果1に対し、教師データが1である割合を表します。これは潅水を検出したものの内、それが本物の潅水であった割合を意味します。これも高いほど良い予測が出来ていると言えます。この例では適合率は14÷(14+11) = 0.560となります。
それでは、4つの学習モデルを比較してみましょう。
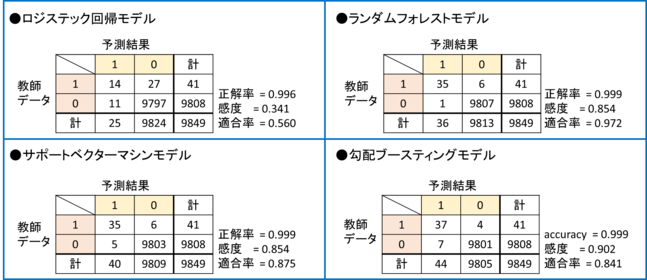
正解率はどのモデルもとても高い値となりました。しかし今回のデータは、教師データ9849中、9808データが「0」つまり「潅水なし」なので、全く潅水を検知出来ないモデル(全て「潅水なし」を予測する)でも正解率は9808÷9849 = 0.995 となる為、モデルの評価には他の指標を見る必要があります。
感度を見てみると、「勾配ブースティングモデル」が最も高い0.902となりました。このモデルが最も実際の潅水を検出してくれる、という意味になります。
一方、適合率を見てみると「ランダムフォレストモデル」が最も高い0.972となりました。これはランダムフォレストが最も誤検出の割合が少ないことを意味します。総括すると、勾配ブースティングが最も潅水を検出してくれるが、検出の正しさはランダムフォレストが最も優秀で、サポートベクターマシンは両者の中間、ロジスティック回帰は今回の分類問題にはあまり適していない、と言うことになりそうです。使用用途に合わせてモデルを選ぶことが必要になります。
一般に感度と、適合率はトレードオフの関係にあります。感度を高くしようとすると、適合率は低下し、その逆も然りです。直感的にも検出性を高めようとすると、ちょっとした変化を誤検出してしまう、と言うのはイメージが付くと思います。このバランスを取るように検出の閾値の調整を試してみたので、ご紹介します。
ここでは「ランダムフォレストモデル」について、潅水検出の閾値を変化させた時の感度と適合率の変化について紹介します。先ほど説明したように、今回の分析ではランダムフォレストは、適合率は最も高いが、感度は勾配ブースティングに劣る、という結果でした。閾値を変更することで、感度を上げることを考えます。
まず、「閾値」についてですが、各学習モデルは、テストデータに対し、「潅水あり」の「確率」を算出します。この「確率」は0~1の間の値で、0.5を境に「潅水あり」「潅水なし」を判定しています。例えば、あるデータに対し、0.3という値を算出したら、0.3<0.5なので「潅水なし」と判定します。この判定閾値を下げてやると、より「潅水あり」を予測しやすくなり、感度が高くなります。しかしむやみに閾値を下げると当然誤検出が増えますので、“ちょうどいいところ”を探してみます。下記に閾値に対する「感度」と「適合率」の変化のグラフを示します。
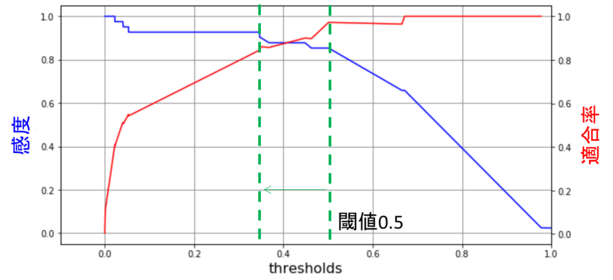
グラフより、感度と適合率のトレードオフが確認できます。現在閾値は0.5に設定しているので、これを0.35にしてみましょう。結果を下に示します。比較のため、勾配ブースティングモデルと、閾値0.5のランダムフォレストモデルも再掲します。
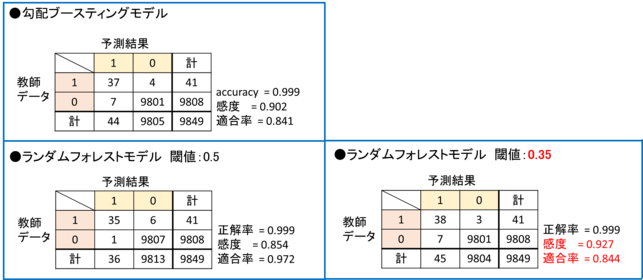
閾値0.5に比べ、感度を向上させることが出来ました。「潅水あり1」と予測した数は36から45へ増え、潅水を検出しやすいモデルになったと言えます。当然適合率は減少しています。勾配ブースティングモデルと比較すると、適合率は同程度で、感度を若干向上させたモデルが出来たと言えそうです。
検出性を優先するなら閾値0.35、誤検出を極力避けたいなら閾値0.5を選ぶと言うように、閾値も使用用途に合った選択が必要となります。
今回、土壌水分量データから機械学習手法を用いて「潅水」を検出することを検討しました。学習モデルや閾値の選び方で結果が変わってくるので、実運用に適用する際は、使用用途に合わせた選択が必要となります。
本検討の今後の応用としては、未来の土壌水分量の予測を行い、潅水計画を自動で作成し、計画に基づいて潅水を実施、潅水を検出、作業記録へ自動反映、という潅水に関わる業務を統合的に管理できるのではないか、と考えています。